The progress in Artificial Intelligence, particularly in Natural Language Processing (NLP), have been remarkable in recent years. One of the core innovations that made this progress possible is the multi-head attention layer. This concept lies at the heart of modern AI models, including the Transformer architecture, which powers tools like ChatGPT, BERT, and many others.
If you’re looking to dive deeper into concepts like these, enrolling in a comprehensive Artificial Intelligence Course in Trivandrum at FITA Academy can provide hands-on learning and expert guidance. In this blog, we will explore what a multi-head attention layer is, how it works, and why it is such a powerful concept in deep learning.
Understanding Attention in AI
Before diving into multi-head attention, it’s important to understand the idea of attention in AI models. To put it simply, attention allows a model to concentrate on the most important aspects of the input while making predictions or producing an output. For example, when translating a sentence from English to French, the model must pay attention to the correct words in the source language to generate the right words in the target language.
Attention enables the model to allocate varying weights to different input components according to their significance for the specific task. This mechanism helps AI models process sequences more efficiently and with greater accuracy. To understand concepts like attention mechanisms in depth, an Artificial Intelligence Course in Kochi can offer you valuable knowledge and practical experience led by professionals from the industry.
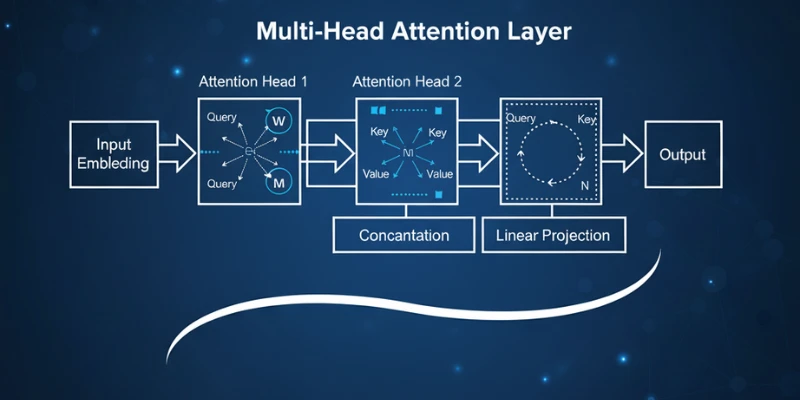
What is Multi-Head Attention?
Multi-head attention builds upon the concept of the attention mechanism. Instead of calculating attention once, the model does it multiple times in parallel, with each attention operation known as a “head.” Each head learns to focus on different parts of the input sequence. These heads work independently and are later combined to form the final output.
The idea is that different heads can capture different types of relationships within the data. One head might learn word associations, while another might focus on sentence structure. Together, they give the model a richer and more detailed understanding of the input.
This parallel attention structure allows the model to gather multiple perspectives at the same time, leading to better comprehension and more robust predictions.
Why Use Multi-Head Attention?
There are several reasons why multi-head attention is so widely used in AI models today. Here are the key benefits:
1. Captures Multiple Relationships
Single-head attention may be limited in the kind of information it can extract. Multi-head attention overcomes this by allowing the model to look at the data from several viewpoints. This leads to a deeper and more flexible understanding of the input. For those interested in mastering such advanced AI concepts, signing up for an AI Course in Ahmedabad can be an excellent step toward building a strong foundation in modern machine learning techniques.
2. Improves Model Performance
By processing information in parallel, multi-head attention helps the model understand context more effectively. This is especially useful in tasks like translation, summarization, or question-answering, where the relationships between words or sentences can be complex.
3. Enhances Learning Efficiency
Each attention head in a multi-head setup can specialize in learning a specific aspect of the data. This division of focus allows the model to learn more efficiently and generalize better across different tasks or datasets.
4. Supports Scalability
Multi-head attention is designed to work well with large models and massive datasets. It distributes computation across different heads, which makes it easier to scale the architecture for more powerful and complex applications.
Real-World Impact
Multi-head attention is a critical component in models like GPT, BERT, and other Transformer-based systems. These models are behind many AI-powered tools we use today, such as chatbots, language translators, and content generators.
Thanks to multi-head attention, these models can understand context better, respond more naturally, and generate outputs that are coherent and relevant. Whether it’s writing an email or answering a complex question, multi-head attention helps AI perform at a human-like level.
Multi-head attention is more than just a technical detail. It is one of the core ideas that has enabled modern AI models to reach new heights. By allowing models to focus on different aspects of the input in parallel, it boosts both accuracy and performance. To gain a deeper understanding of such foundational AI concepts, joining an Artificial Intelligence Course in Chandigarh can help you build practical skills and stay ahead in this fast-evolving field.
As AI continues to evolve, concepts like multi-head attention will remain central to building smarter, more capable systems. If you want to understand how today’s most powerful language models work, learning about multi-head attention is a great place to start.
Also check: Key Benefits of Acquiring Artificial Intelligence Skills